Initialization Of Deep Feedfoward Networks
Jefkine, 1 August 2016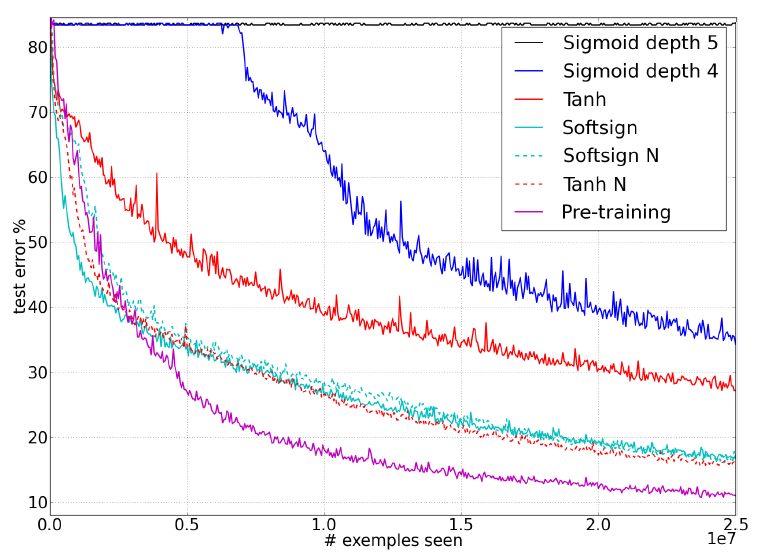
Introduction
Deep multi-layered neural networks often require experiments that interrogate different initialization routines, activations and variation of gradients across layers during training. These provide valuable insights into what aspects should be improved to aid faster and successful training.
For Xavier and Bengio (2010) [1] the objective was to better understand why standard gradient descent from random initializations was performing poorly in deep neural networks. They carried out analysis driven by investigative experiments that monitored activations (watching for saturations of hidden units) and gradients across layers and across training iterations. They evaluated effects on choices of different activation functions (how it might affect saturation) and initialization procedure (with lessons learned from unsupervised pre-training as a form of initialization that already had drastic impact)
A new initialization scheme that brings substantially faster convergence was proposed. In this article we discuss the algorithm put forward by Xavier and Bengio (2010) [1]
Gradients at Initialization
Earlier on, Bradley (2009) [2] found that in networks with linear activation at each layer, the variance of the back-propagated gradients decreases as we go backwards in the network. Below we will look at theoretical considerations and a derivation of the normalized initialization.
Notation
- is the activation function. For the dense artificial neural network, a symmetric activation function with unit derivative at is chosen. Hyperbolic tangent and softsign are both forms of symmetric activation functions.
- is the activation vector at layer ,
- is the argument vector of the activation function at layer ,
- is the weight vector connecting neurons in layer with neurons in layer .
- is the bias vector on layer .
- is the network input.
From the notation above, it is easy to derive the following equations of back-propagation
The variances will be expressed with respect to the input, output and weight initialization randomness. Considerations made include:
- Initialization occurs in a linear regime
- Weights are initialized independently
- Input feature variances are the same
- There is no correlation between our input and our weights and both are zero-mean.
- All biases have been initialized to zero.
For the input layer, with components each from training samples. Here the neurons are linear with random weights outputting .
The output can be shown by the equations below:
Given and are independent, we can show that the variance of their product can be given by:
Considering our inputs and weights both have mean , Eqn. simplifies to
and are all independent and identically distributed, we can therefore show that:
Further, lets now look at two adjacent layers and . Here, is used to denote the size of layer layer . Applying the derivative of the activation function at yields a value of approximately one.
Then using our prior knowledge of independent and identically distributed and , we have.
in Eqn. , is the shared scalar variance of all weights at layer . Taking these observations into consideration, a network with layers, will have the following Eqns.
We would then like to steady the variance such there is equality from layer to layer. From a foward-propagation point of view, to keep information flowing we would like that
From a back-propagation point of view, we would like to have:
For Eqns. and to hold, the shared scalar variances in Eqn. should be . This is the same as trying to ensure the variances of the input and output are consistent (realize that the technique used here helps avoid reducing or magnifying the signals exponentially hence mitigating the exploding or vanishing gradient problem):
As a compromise between the two constraints (representing back-propagation and foward-propagation), we might want to have $$ \begin{align} \forall (i), \quad \frac{2}{n_{i} + n_{i+1}} \tag {12} \end{align} $$
In the experimental setting chosen by Xavier and Bengio (2010) [1], the standard initialization weights at each layer using the commonly used heuristic: $$ \begin{align} W_{i,j} \sim U \left[ -\frac{1}{\sqrt n}, \frac{1}{\sqrt n} \right], \tag {13} \end{align} $$
where is the uniform distribution in the interval and is the size of the previous layer (the number of columns of ).
For uniformly distributed sets of weights with zero mean, we can use the formula for variance of a uniform distribution to show that:
Substituting Eqn. into an Eqn. of the form yields:
The weights have thus been initialized from the uniform distribution over the interval $$ \begin{align} W \sim U \left[ -\frac{\sqrt 3}{\sqrt {n}}, \frac{\sqrt 3}{\sqrt {n}} \right] \tag{15} \end{align} $$
The normalization factor may therefore be important when initializing deep networks because of the multiplicative effect through layers. The suggestion then is of an initialization procedure that maintains stable variances of activation and back-propagated gradients as one moves up or down the network. This is known as the normalized initialization $$ \begin{align} W \sim U \left[ -\frac{\sqrt 6}{\sqrt {n_{i} + n_{i+1}}}, \frac{\sqrt 6}{\sqrt {n_{i} + n_{i+1}}} \right] \tag{16} \end{align} $$
The normalized initialization is a clear compromise between the two constraints involving and (representing back-propagation and foward-propagation), If you used the input , the normalized initialization would look as follows: $$ \begin{align} W \sim U \left[ -\frac{\sqrt 6}{\sqrt {n + m}}, \frac{\sqrt 6}{\sqrt {n + m}} \right] \tag{17} \end{align} $$
Conclusions
In general, from Xavier and Bengio (2010) [1] experiments we can see that the variance of the gradients of the weights is the same for all the layers, but the variance of the back-propagated gradient might still vanish or explode as we consider deeper networks.
Applications
The initialization routines derived here, more famously known as “Xavier Initialization” have been successfully applied in various deep learning libraries. Below we shall look at Keras a minimalist, highly modular neural networks library, written in Python and capable of running on top of either TensorFlow or Theano.
The initialization routine here is named “glorot_” following the name of one of the authors Xavier Glorot [1]. In the code snippet below, glorot_normal is the implementation of Eqn. while glorot_uniform is the equivalent implementation of Eqn.
def get_fans(shape):
fan_in = shape[0] if len(shape) == 2 else np.prod(shape[1:])
fan_out = shape[1] if len(shape) == 2 else shape[0]
return fan_in, fan_out
def glorot_normal(shape, name=None):
''' Reference: Glorot & Bengio, AISTATS 2010
'''
fan_in, fan_out = get_fans(shape)
s = np.sqrt(2. / (fan_in + fan_out))
return normal(shape, s, name=name)
def glorot_uniform(shape, name=None):
fan_in, fan_out = get_fans(shape)
s = np.sqrt(6. / (fan_in + fan_out))
return uniform(shape, s, name=name)References
- Glorot Xavier, and Yoshua Bengio. “Understanding the difficulty of training deep feedforward neural networks.” Aistats. Vol. 9. 2010. [PDF]
- Bradley, D. (2009). Learning in modular systems. Doctoral dissertation, The Robotics Institute, Carnegie Mellon University.
- Wikipedia - Variance: “Product of independent variables”.