Initialization Of Feedfoward Networks
Jefkine, 27 July 2016Introduction
Weight initialization has widely been recognized as one of the most effective approaches in improving training speed of neural networks. Yam and Chow [1] worked on an algorithm for determining the optimal initial weights of feedfoward neural networks based on the Cauchy’s inequality and a linear algebraic method.
The proposed method aimed at ensuring that the outputs of neurons existed in the active region (i.e where the derivative of the activation function has a large value) while also increasing the rate of convergence. From the outputs of the last hidden layer and the given output patterns, the optimal values of the last layer of weights are evaluated by a least-squares method.
With the optimal initial weights determined, the initial error becomes substantially smaller and the number of iterations required to achieve the error criterion is significantly reduced.
Yam and Chow had previously worked on other methods with this method largely seen as an improvement on earlier proposed methods [2] and [3]. In [1] the rationale behind their proposed approach was to reduce the initial network error while preventing the network from getting stuck with the initial weights.
Weight Initialization Method
Consider a multilayer neural network with fully interconnected layers. Layer consists of neurons in which the last neuron is a bias node with a constant output of .
Notation
- is the layer where is the first layer and is the last layer.
- is the output vector at layer $$ \begin{align} o_{i,j}^{l} &= \sum_{i =1}^{n_l+1} w_{i\rightarrow j}^l a_{p,i}^l \end{align} $$
- is the weight vector connecting neuron of layer with neuron of layer .
- is the activated output vector for a hidden layer . $$ \begin{align} a_{p,j}^{l} &= f(o_{p,j}^{l-1}) \end{align} $$
- is the activation function. A sigmoid function with the range of between and is used as the activation function. $$ \begin{align} f(x) = \frac{1}{1 + e^{(-x)}} \end{align} $$
- is the total number of patterns for network training.
- where is the matrix of all given inputs with dimensions rows and columns. All the last entries of the matrix are a constant .
- is the weight matrix between layers and .
- is the matrix representing all entries of the last output layer given by $$ \begin{align} a_{p,j}^L &= f(o_{p,j}^{L-1}) \end{align} $$
- is the matrix of all the targets with dimensions rows and columns.
The output of all hidden layers and the output layer are obtained by propagating the training patterns through the network.
Learning will then be achieved by adjusting the weights such that is as close as possible or equals to .
In the classical back-propagation algorithm, the weights are changed according to the gradient descent direction of an error surface (taken on the output units over all the patterns) using the following formula: $$ \begin{align} E_p &= \sum_{p =1}^P \left( \frac{1}{2} \sum_{j}^{n_L}\left(t_{p,j} - a_{p,j}\right)^2 \right) \end{align} $$
Hence, the error gradient of the weight matrix is:
If the standard sigmoid function with a range between 0 and 1 is used, the rule of changing the weights cane be shown to be: $$ \begin{align} \Delta w_{i,j}^l =&\ -\frac{\eta}{P} \sum_{p =1}^P \delta_{p,j}^{l}a_{p,i}^{l} \end{align} $$ where is the learning rate (or rate of gradient descent)
The error gradient of the input vector at a layer is defined as $$ \begin{align} \delta_{p,j}^l = \frac{\partial E_p}{\partial o_{p,j}^l} \end{align} $$
The error gradient of the input vector at the last layer is
Derivative of a sigmoid . This result can be substituted in equation as follows:
For the other layers i.e , the scenario is such that multiple weighted outputs from previous the layer lead to a unit in the current layer yet again multiple outputs.
The weight connects neurons and , the sum of the weighed inputs from neuron is denoted by where iterates over all neurons connected to
Derivative of a sigmoid . This result can be substituted in equation as follows:
From Eqns. and , we can observe that the change in weight depends on outputs of neurons connected to it. When outputs of neurons are or , the derivative of the activation function evaluated at this value is zero. This means there will be no weight change at all even if there is a difference between the value of the target and the actual output.
The magnitudes required to ensure that the outputs of the hidden units are in the active region and are derived by solving the following problem: $$ \begin{align} 1 - \overline{t} \leq a_{p,j}^{l+1} \leq \overline{t} \tag 6 \end{align} $$
A sigmoid function also has the property which means Eqn can also be written as: $$ \begin{align} -\overline{t} \leq a_{p,j}^{l+1} \leq \overline{t} \tag 7 \end{align} $$
Taking the inverse of Eqn such that and results in $$ \begin{align} -\overline{s} \leq o_{p,j}^{l} \leq \overline{s} \tag 8 \end{align} $$
The active region is then assumed to be the region in which the derivative of the activation function is greater than of the maximum derivative, i.e. $$ \begin{align} \overline{s} \approx 4.59 \qquad \text{for the standard sigmoid function} \tag {9a} \end{align} $$
and $$ \begin{align} \overline{s} \approx 2.29 \qquad \text{for the hyperbolic tangent function} \tag {9b} \end{align} $$
Eqn can then be simplified to $$ \begin{align} (o_{p,j}^{l})^2 \leq \overline{s}^2 \qquad or \qquad \left(\sum_{i =1}^{n_l+1} a_{p,i}^{l} w_{i,j}^{l} \right)^2 \leq \overline{s}^2 \tag {10} \end{align} $$
By Cauchy’s inequality, $$ \begin{align} \left(\sum_{i =1}^{n_l+1} a_{p,i}^{l} w_{i,j}^{l} \right)^2 \quad \leq \quad \sum_{i =1}^{n_l+1} (a_{p,i}^{l})^2 \sum_{i =1}^{n_l+1} (w_{i,j}^{l} )^2 \tag {11} \end{align} $$
Consequently, Eqn is replaced by $$ \begin{align} \sum_{i =1}^{n_l+1} (a_{p,i}^{l})^2 \sum_{i =1}^{n_l+1} (w_{i,j}^{l} )^2 \leq \overline{s}^2 \tag {12} \end{align} $$
If is a large number and if the weights are values between to with zero mean independent identical distributions, the general weight formula becomes: $$ \begin{align} \sum_{i =1}^{n_l+1} (w_{i,j}^{l} )^2 \approx \left\lgroup \matrix{number\cr of\cr weights} \right\rgroup * \left\lgroup \matrix{variance\cr of\cr weights} \right\rgroup \tag {13} \end{align} $$
For uniformly distributed sets of weights we apply the formula for variance of a uniform distribution, and subsequently show that.
This can then be used in the next Eqn as:
By substituting Eqn into
For sets of weights with normal distribution and is a large number, $$ \begin{align} \sum_{i =1}^{n_l+1} (w_{i,j}^{l} )^2 \quad \approx (n_l+1) * (\theta_p^l)^2 \quad \approx \frac{(n_l+1)}{1}(\theta_p^l)^2 \tag {16} \end{align} $$
By substituting Eqn into
In the proposed algorithm therefore, the magnitude of weights for pattern is chosen to be:
For different input patterns, the values of are different, To make sure the outputs of hidden neurons are in the active region for all patterns, the following value is selected $$ \begin{align} \theta^l &= \min_{\rm p=1,\dotsm,P}(\theta_p^l) \tag{19} \end{align} $$
Deep networks using of sigmiod activation functions exhibit the challenge of exploding or vanishing activations and gradients. The diagram below gives us a perspective of how this occurs.
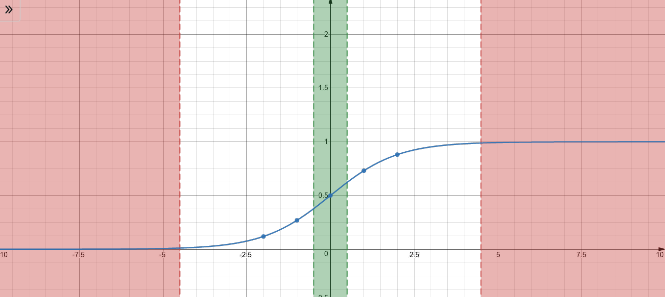
- When the parameters are too large - the activations become larger and larger (i.e tend to exist in the red region above), then your activations will saturate and become meaningless, with gradients approaching .
- When the parameters are too small - the activations keep dropping layer after layer (i.e tend to exist in the green region above). At levels closer to zero the sigmoid activation function become more linear. Gradually the non-linearity is lost with derivatives of constants being and hence no benefit of multiple layers.
Summary Procedure of The Weight Initialization Algorithm
- Evaluate using the input training patterns by applying Eqns and with
- The weights are initialized by a random number generator with uniform distribution between to or normal distribution
- Evaluate by feedforwarding the input patterns through the network using
- For
- Evaluate using the outputs of layer , i.e and applying Eqns and
- The weights are initialized by a random number generator with uniform distribution between to or normal distribution
- Evaluate by feedforwarding the outputs of through the network using
-
After finding or , we can find the last layer of weights by solving the following equation using a least-squares method, $$ \begin{align} \Vert A^{L-1}W^{L-1} - S \Vert_2 \tag{20} \end{align} $$
-
is a matrix, which has entries, $$ \begin{align} s_{i,j} = f^{-1}(t_{i,j}) \tag{21} \end{align} $$
-
where are the entries of target matrix .
-
The weight initialization process is then completed. The linear least-squares problem shown in Eqn can be solved by QR factorization using Householder reflections [4].
In the case of an overdetermined system, QR factorization produces a solution that is the best approximation in a least-squares sense. In the case of an under-determined system, QR factorization computes the minimal-norm solution.
Conclusions
In general the proposed algorithm with uniform distributed weights performs better than the algorithm with normal distributed weights. The proposed algorithm is also applicable to networks with different activation functions.
It is worth noting that the time required for the initialization process is negligible when compared with training process.
References
- A weight initialization method for improving training speed in feedforward neural network Jim Y.F. Yam, Tommy W.S. Chow (1998) [PDF]
- Y.F. Yam, T.W.S. Chow, Determining initial weights of feedforward neural networks based on least-squares method, Neural Process. Lett. 2 (1995) 13-17.
- Y.F. Yam, T.W.S. Chow, A new method in determining the initial weights of feedforward neural networks, Neurocomputing 16 (1997) 23-32.
- G.H. Golub, C.F. Van Loan, Matrix Computations, The Johns Hopkins University Press, Baltimore, MD, 1989