Formulating The ReLu
Jefkine, 24 August 2016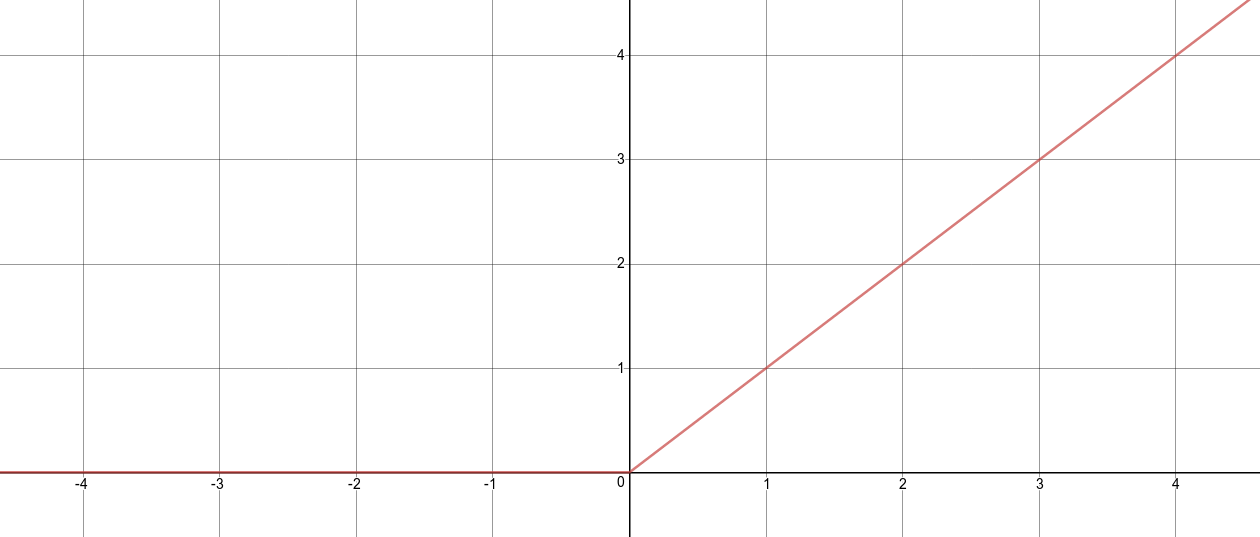
ReL Definition
The Rectified Linear Function (ReL) is a max function given by where is the input. A more generic form of the ReL Function as used in neural networks can be put together as follows:
In Eqn. above, is the input of the nonlinear activation on the th channel, and is the coefficient controlling the slope of the negative part. in indicates that we allow the nonlinear activation to vary on different channels.
The variations of rectified linear (ReL) take the following forms:
- ReLu: obtained when . The resultant activation function is of the form
- PReLu: Parametric ReLu - obtained when is a learnable parameter. The resultant activation function is of the form
- LReLu: Leaky ReLu - obtained when i.e when is a small and fixed value [1]. The resultant activation function is of the form
- RReLu: Randomized Leaky ReLu - the randomized version of leaky ReLu, obtained when is a random number sampled from a uniform distribution i.e . See [2].
From Sigmoid To ReLu
A sigmoid function is a special case of the logistic function which is given by where is the input and it’s output boundaries are .
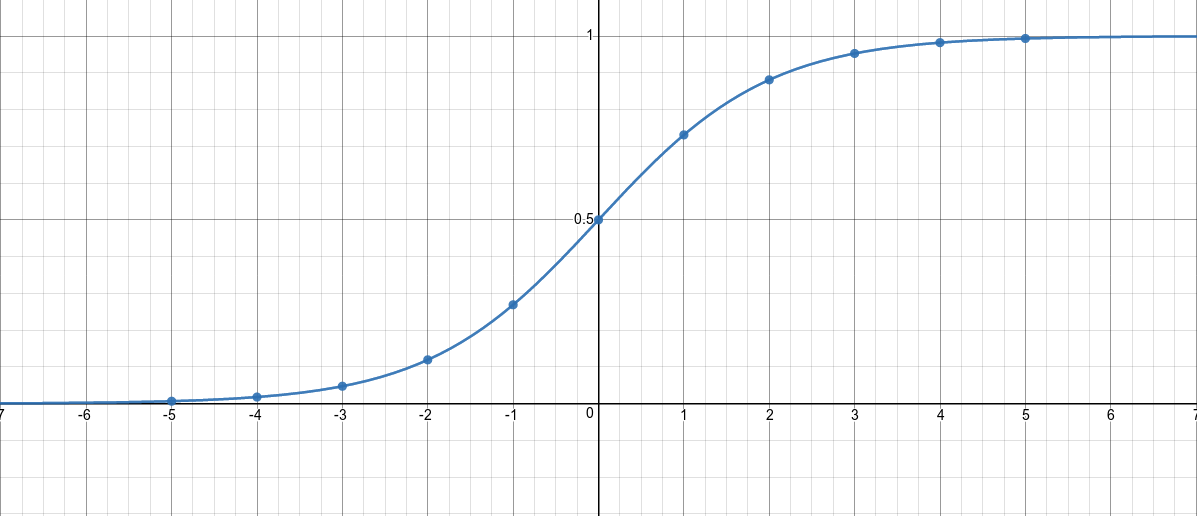
Take an in-finite number of copies of sigmoid units, all having the same incoming and outgoing weights and the same adaptive bias . Let each copy have a different, fixed offset to the bias.
With offsets that are of the form , we obtain a set of sigmoids units with different biases commonly referred to as stepped sigmoid units (SSU). This set can be illustrated by the diagram below:
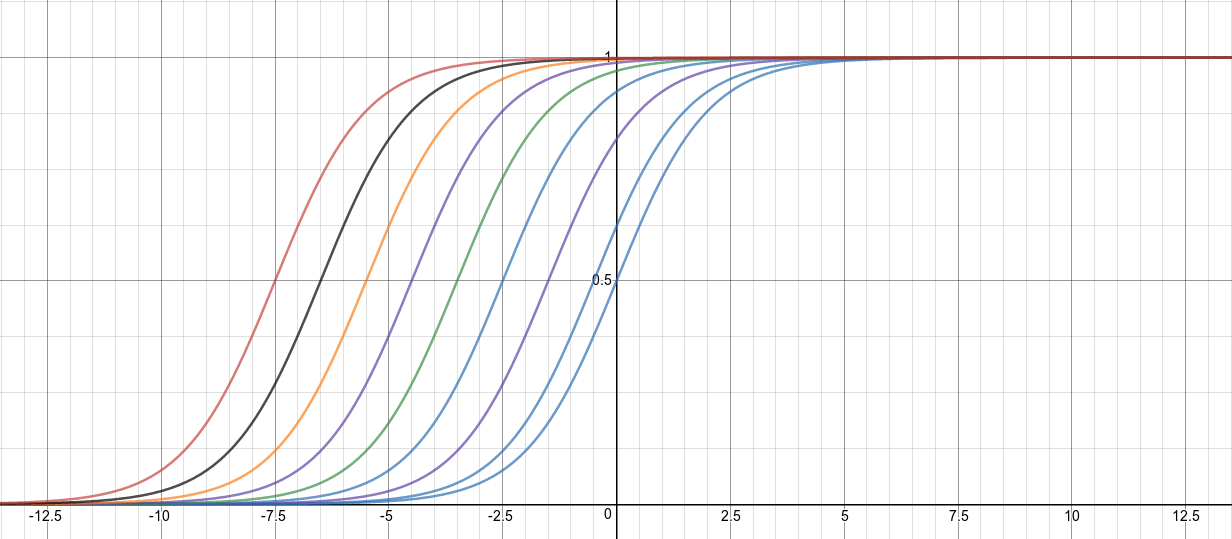
The illustration above represents a set of feature detectors with potentially higher threshold. Given all have the same incoming and outgoing weights, we would then like to know how many will turn on given some input. This translates to the same as finding the sum of the logistic of all these stepped sigmoid units (SSU).
The sum of the probabilities of the copies is extremely close to i.e. $$ \begin{align} \sum_{n=1}^{\infty} \text{logistic} \, (x + 0.5 - n) \approx \log{(1 + e^x)} \tag {2} \end{align} $$
Actually if you take the limits of the sum and make it an intergral, it turns out to be exactly . See Wolfram for more info.
Now we know that is behaving like a collection of logistics but more powerful than just one logistic as it does not saturate at the top and has a more dynamic range.
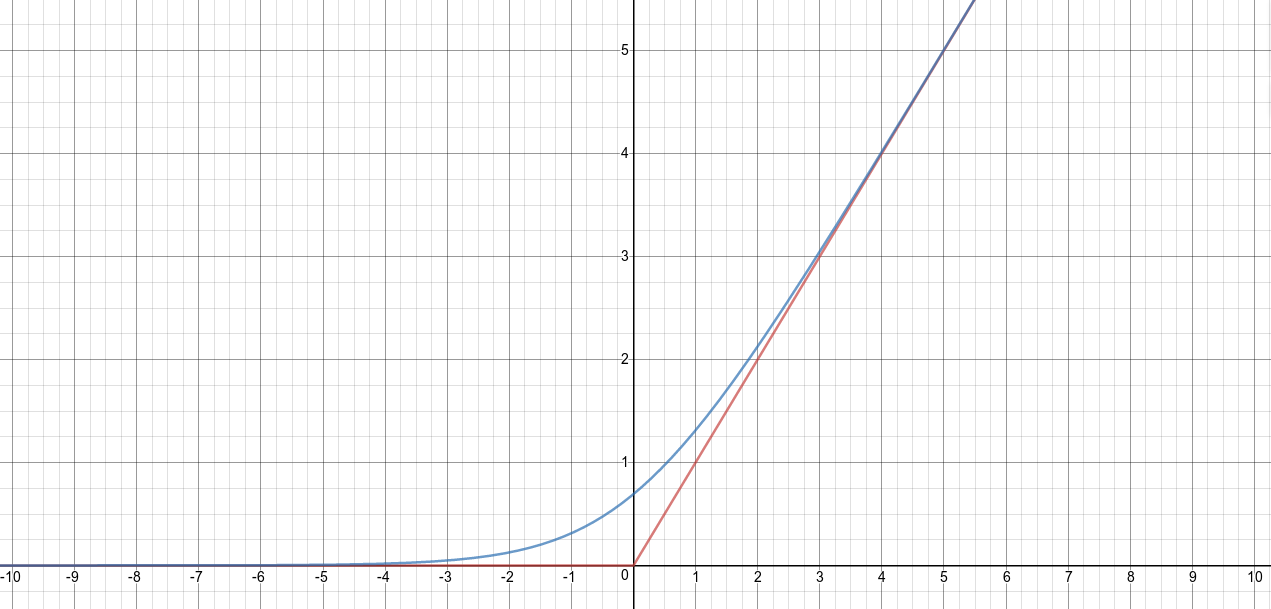
is known as the softplus function and can be approximated by max function (or hard max) i.e . The max function is commonly known as Rectified Linear Function (ReL).
In the illustration below the blue curve represents the softplus while the red represents the ReLu.
Advantages of ReLu
ReLu (Rectified Linear Units) have recently become an alternative activation function to the sigmoid function in neural networks and below are some of the related advantages:
- ReLu activations used as the activation function induce sparsity in the hidden units. Inputs into the activation function of values less than or equal to , results in an output value of . Sparse representations are considered more valuable.
- ReLu activations do not face gradient vanishing problem as with sigmoid and tanh function.
- ReLu activations do not require any exponential computation (such as those required in sigmoid or tanh activations). This ensures faster training than sigmoids due to less numerical computation.
- ReLu activations overfit more easily than sigmoids, this sets them up nicely to be used in combination with dropout, a technique to avoid overfitting.
References
- A. L. Maas, A. Y. Hannun, and A. Y. Ng. “Rectifier nonlinearities improve neural network acoustic models.” In ICML, 2013. [PDF]
- Xu, Bing, et al. “Empirical Evaluation of Rectified Activations in Convolution Network.” [PDF]
- Nair, Vinod, and Geoffrey E. Hinton. “Rectified linear units improve restricted boltzmann machines.” Proceedings of the 27th International Conference on Machine Learning (ICML-10). 2010. [PDF]